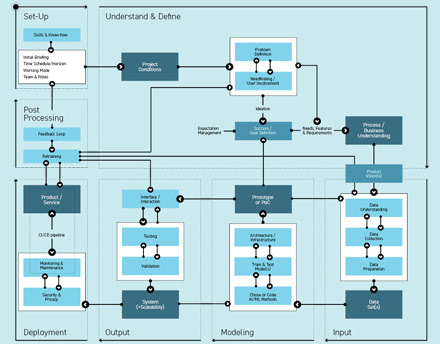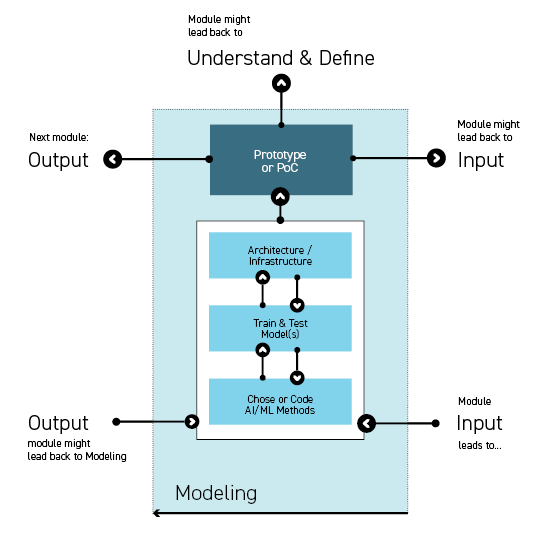
1. Chose & Code AI/ML method
Based on the problem statement and the data set, an AI/ML method that solves the problem can be chosen. Sometimes this is the starting point for a couple of projects where problems and data are already given, without going through the steps above first. It is possible to combine different AI/ML methods or try different approaches in order to verify the best solution for the given problem.
Based on the problem statement and the data set, an AI/ML method that solves the problem can be chosen. Sometimes this is the starting point for a couple of projects where problems and data are already given, without going through the steps above first. It is possible to combine different AI/ML methods or try different approaches in order to verify the best solution for the given problem.
+ Machine (Deep) Learning types: For an overview of different AI/ML methods (16) cheat sheets can be very useful.
2. Train & Test models
The data set(s) from module ‘Input’ needs to be separated into training, validation and testing data to judge the AI/ML model’s performance. The training data is used for model-training, as the name implies. The validation data set is used as a reference for the model’s performance. The testing data is provided to a trained and validated model in order to finally test the model with a ‘new’ data set (see Fig. 8.9). This is very important to understand, because it means that model accuracy is always tested and compared against data from the past that is already available to the development team and that splitting the data into training, validation and test set needs to be allowed for in the amount of data points needed to actually train a model. The validation and testing data cannot be included in the training data set, depending on the division ratio (½:¼:¼) validation and testing data reduces the amount of data overall on which the model can be trained. This is why more data is better than little data.
+ Existing tools: It is very common in AI/ML practice to use a model that has been pretrained and targeted towards the specific use case (e.g. GPT3 - Generative Pre-trained Transformer used for text generation, BERT - Bidirectional Encoder Representations from Transformers used for natural language processing, GAN - Generative Adversarial Network used for image generation, R-CNN - Region-based Convolutional Network used for object recognition). It is then used with its very own data set. The data set is separated into training data and validation data in order to judge the model’s performance, as mentioned above. Most AI/ML modeling frame- works have a frontend that incorporates some visualization features in order to judge the model’s accuracy and performance (heat maps e.g.). With streamlit, and shiny, it is easy to quickly prototype and share data apps. Other relevant tools and services in that regard are for coding: python, processing; autoML solutions: AWS, Azure, IBM, google teachable machine, lobe and for designers specifically: wekinator and Delft AI toolkit. The tools section is referring to existing tools (17) overview.
3. Architecture / Infrastructure
Many AI/ML models use a lot of computing power and can therefore not be trained on a private PC but depend on cloud computing. Also, when thinking about a productive system and automation of data upload, as well as other features, it is necessary to take the systems architecture and infrastructure into account. It can be helpful to integrate an IT department with this decision in advance.
+ External vs. internal solution: A decision has to be made whether to use a 3rd party solution, which might already provide a frontend, architecture and infrastructure set up, as well as maintenance and monitoring capabil- ities. On contrary, the flexibility of an in-house development may be the better way to go. Both solutions have their pros and cons, which need to be weighed and acted upon.
+ Cloud vs. on premise: Data privacy and security might be the main decision drivers here. Take the cost for a cloud service, compared to setting up the hardware for an on premise solution, into account.
Many AI/ML models use a lot of computing power and can therefore not be trained on a private PC but depend on cloud computing. Also, when thinking about a productive system and automation of data upload, as well as other features, it is necessary to take the systems architecture and infrastructure into account. It can be helpful to integrate an IT department with this decision in advance.
+ External vs. internal solution: A decision has to be made whether to use a 3rd party solution, which might already provide a frontend, architecture and infrastructure set up, as well as maintenance and monitoring capabil- ities. On contrary, the flexibility of an in-house development may be the better way to go. Both solutions have their pros and cons, which need to be weighed and acted upon.
+ Cloud vs. on premise: Data privacy and security might be the main decision drivers here. Take the cost for a cloud service, compared to setting up the hardware for an on premise solution, into account.
Steps 1 to 3 heavily depend on and influence each other. Sometimes the borders are blurred and activities cannot be separated as stated. The level of knowledge on the designer’s side is vital for the involvement of their expertise in this module. Coding skills would help here but are not necessary. AutoML solutions provide a framework that can also be used by designers. However, prototyping in a low fidelity and fail fast manner is hardly possible. Model behavior and performance need to be measured with real data. In this module, ML engineers maximize their expertise.
Outcome: (High fidelity) Prototype/PoC or MVP
This module is meant to prove, or in later iterations make sure, that whether or not the data input creates a meaningful model performance that the AI/ML approach is the way forward. However, a bad model performance can be for different reasons. One reason can be the wrong choice of AI/ML method, in which case, it is necessary to start over again with this module. It is also possible that the problem lies within the data input. Going through the ‘Input’ module is the path to follow in this case. It can also be helpful to have second thoughts on the success and goal definitions, making sure the error metric or level of accuracy are not too optimistic. If the model performance is bad, it is necessary to start over again. Or if additional iterations are not going anywhere, this marks the exit point for this project.